
|
Resident of the world, traveling the road of life
|





Today's links
- Better to beg forgiveness: Don't ring the doorbell at the house of no unless you absolutely must.
- Hey look at this: Delights to delectate.
- Object permanence: RIP Poul Anderson; P2P at PC Forum; Waitress handed her own stolen ID by carded diner; PDX bans fixies; Digital Economy Bill was a stitch up; NZ copyright disconnection flowchart; Fry v Widdicombe on Catholic Church; Moxie Marlinspike profile; V&A bans sketching; Gernsback's intro to the first Amazing Stories; "Simplicity."
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Better to beg forgiveness (permalink)
From its inception, I've loved Creative Commons. I hung out with Lisa Rein, Matt Haughey and Aaron Swartz while they coded up the first version of the site, and my first novel, Down and Out in the Magic Kingdom, was the first professionally published text ever released under a CC license, just weeks after CC itself launched:
In those early days, CC licenses were primarily of interest to people who were steeped in copyright law, lore and litigation; so many of the early debates about these licenses turned on esoteric (but important!) questions about copyright; for example, how CC would interact with copyright's "limitations and exceptions."
You see, copyright has never meant the absolute right to control all uses of a work. Every system of copyright includes a set of "limitations and exceptions" for people making use of copyrighted works without permission, even if the copyright holder objects to that use. The best-known example of this is "fair use," a concept from American law.
Fair use is (potentially) extremely broad, but it's also extremely "fact-intensive" – that's the phrase lawyers use to describe the kind of legal question whose answer is almost always "it depends." Fair use might let you copy the entirety of a work, even for a commercial purpose. It might let you create new works based on existing works. It might let you do these things specifically to discourage people from buying the original. But…it depends.
If you know anything about fair use, it's probably something about a "four-step test" used to determine if a usage is fair. These four steps are just questions a judge might ask of someone who's been sued for copyright infringement, but who claims that they were making a fair use. The questions are:
I. What was the "nature and purpose" of your use? Were you doing something "transformative?" Were you criticizing the work? Were you using the work for educational purposes?
II. What was the nature of the work you used? Was it primarily factual (like a news article) or creative (like a short story)?
III. How much of the work did you take? Did you take more than you needed to transform the work, to accomplish your criticism, to teach someone?
IV. What impact did your use have on the original? Did the copyright holder lose money as a result of your use?
https://fairuse.stanford.edu/overview/fair-use/four-factors/
These questions are indeed enshrined in US copyright law, but (for better and for worse) you can't figure out if a use is "fair" just by asking these questions. Fair use is ultimately subject to "the rule of reason," a legal principle meaning that the law shouldn't result in obviously stupid restrictions. What's "obviously stupid?" Well, that's the tricky part – you'll have to convince a judge!
For example, the author of a book called The Wind Done Gone was sued for taking the characters, plot and setting of Gone With the Wind in order to tell the same story from the perspective of the enslaved Africans who were denied agency and moral consideration in the original. The court found for The Wind Done Gone:
https://en.wikipedia.org/wiki/The_Wind_Done_Gone
Wind Done Gone took the "heart" of Gone With the Wind (III), but then again, Done Gone was highly transformative (I), Gone With was also a work of fiction, entitled to the highest level of protection (II). Even worse, the point of Done Gone was to point out the gross defects in Gone With (I) and thus directly undermine sales and licensing for the original (IV). Anyone who claims you can answer fair use controversies by running through the four factors as though they were a checklist really doesn't understand fair use:
https://pluralistic.net/2022/02/06/crypto-copyright-%f0%9f%a4%a1%f0%9f%92%a9/
But even after you've acquired an appreciation of the fact-intensive, nuanced flexibility of fair use, you still don't understand copyright's limitations and exceptions. Fair use is important, but there's also "first sale," the doctrine that says that after you buy something, you own it, and copyright can't be used to interfere with your traditional property rights. That's why you can buy and sell used books, paintings, records, and other copyrighted work, even if they are sold with fine print that says you're not allowed to:
https://en.wikipedia.org/wiki/Kirtsaeng_v._John_Wiley_%26_Sons,_Inc.
When it comes to copyright's limitations and exceptions, "fair use" and "first sale" are the big ones, but just as important are the small ones – the really small ones. Like other laws, copyright is subject to the principle of "di minimis" (from a longer Latin phrase that translates as "the law does not concern itself with trifles"):
https://en.wikipedia.org/wiki/De_minimis
Technically, it may be trespassing to step on someone else's yard. But if your shoe brushes up against their lawn while you're walking on the sidewalk out front of their house, it's not trespassing. Or if it is trespassing, it's a di minimis trespass, too small to matter to the law. A lot of potential copyright violations – like taking a picture of a passage in a book and posting it to social media – are so small that we don't need to apply a fair use analysis to them. They're trifles, and "the law does not concern itself with trifles."
These limitations and exceptions all apply without permission from rightsholders. They apply even if they make rightsholders furious. They are your rights, as a member of the public, as a purchaser of a work, or just as someone who whistles a song that's stuck in your head.
And that's where the esoteric early Creative Commons copyright debate comes in. Creative Commons is a way to formally codify and convey permission to use copyrighted works. Without Creative Commons, it's really hard – and expensive – to provide legally reliable permission to someone else to use something you've created.
If I want to let you adapt one of my short stories for the stage, we should both probably hire copyright lawyers at several hundred dollars per hour to draft and review a contract setting out what my permission really means. Worse: even after we've paid the lawyers, neither of us will likely really understand the fine legal technicalities of the deal. We just have to take the lawyers' word for it that the complex jargon in the contract is sufficient for our purposes. Between the complexity and the expense, there are lots of potential creative collaborations that would cost so much to paper over that they're just not worth doing, even if they'd delight everyone involved.
Creative Commons cuts through this with its standardized licenses, which spell out in plain language which permissions are being granted. Even better, these licenses are international, translated into the language and laws of dozens of countries. That means that you can take a CC licensed short story from Japan, animate it using CC licensed 3D models from Italy, set it to a CC licensed soundtrack from Indonesia and release it in Ukraine, and the whole thing just works.
Those uses – turning a story into an animation, using a 3D model, syncing a soundtrack to a video – are all pretty ambitious uses, especially if you're going to make the final result indefinitely available to the general public. It makes sense to paper over these uses, and Creative Commons makes that legal work as simple as linking to your sources and their licenses in your final product.
But there are plenty of uses that don't need licenses – even ambitious ones. Remember Wind Done Gone? There are circumstances when you can adapt someone else's story without permission, relying instead on a limitation or exception to copyright. And of course, there are plenty of trivial uses – pasting a photo into your groupchat, say – that are di minimis and also don't need permission.
These copyright flexibilities are critical. Imagine if you could only criticize someone's work if they gave you permission to do so! From the founding of CC, copyfighters raised serious concerns that CC would teach people that they can only remix other people's work if they have a license, be it a CC license or the kind that you negotiate with a lawyer.
Today – 25 years later!- CC is an unqualified success. Without CC, we wouldn't have Wikipedia! You find CC licenses on Youtube, Flickr, Bandcamp, the Internet Archive, and in many of the most important scholarly and scientific journals in the world.
But, also, 25 years later, the world is even more convinced that you should always ask permission: "better safe than sorry." I don't know if CC contributed to this culture of timidity. More likely, it was bullying copyright trolls who terrorized people into a reflex of asking permission for everything, always.
As the creator of more than 30 books, hundreds of collages, and tens of thousands of essays and blog-posts, I am often on the receiving end of these permission requests.
For example, people often ask me if they can use my CC licensed works in ways that the associated licenses clearly permit. I'm sure the people who email me for permission to do things I've already granted them permission to do think they're being polite, but I really wish they'd stop. When someone asks me if they can make a use permitted by my CC licenses, I need to carefully parse through their use to make sure they're not asking for something more.
This is time-consuming work that often involves several volleys of email just to confirm that, no, they're just asking if they can do something I've already told them they can do. This is not a good use of anyone's time! By all means, drop me a note with a link to something you've remixed from my work. That's fun! It's a lot more fun than making me play detective in order to figure out if you're exceeding the license's permissions.
There are also a lot of requests that clearly amount to fair use and/or di minimis usage. You don't need to email me to get my permission to read a brief passage from one of my books on your Youtube video! You don't need my permission to quote one of my stories in an English exam! What's more, the world would be a lot shittier if you did, so let's not act as though that's reasonable behavior, lest we shift the (already far too restrictive) norms, which might even lead to a legal change.
Finally, there's the people who email me about their desire to make uses that are more (ahem) ambitious, but that no one could possibly find out about or get angry over…except for the fact that they emailed me to ask my permission.
You want to make a tiny bootleg edition of one of my novels for your anarchist book fair? That's totally a copyright infringement, it's super-illegal, and if my publisher found out about it, I'm sure they'd send you a sphincter-puckering legal letter telling you to knock it off (and maybe even demanding that you disgorge the seven dollars, three bottlecaps and eleven cool feathers you took in trade for those pirate books).
But my publisher won't ever find out about it – unless you email me asking for permission. I absolutely cannot give you permission to do this. I have a contract with my publisher promising that I will never authorize someone other than them to publish that book. Once you tell me about your intention to do this, I'm obliged to tell my publisher, so that they can tell you no in language that would strip paint off a barn.
Buying a classroom set of books, but you also want to paste chunks of one of my books into your educational institution's classroom intranet for use as a teaching aid? There's no way my publisher would ever find out you did that, and if they did, sure, you'd also get a blood-curdling legal letter. But dude, all my books are DRM-free. You could have just pasted the text into your CMS. In what universe is my publisher going to pay one of their lawyers to review, adjudicate and paper over your request to make a use that you're not proposing to pay them for?
Let's be clear: I'm not giving you permission to pirate my work. I already spend far too much of my time chasing down dickheads who sell competing editions of my books on Amazon and Audible. I'm sick to the back teeth of wrangling Ingram's takedown process to get rid of bootleg print editions of my books.
What I'm saying is, all of your interactions with copyrighted works need not involve the author and publisher. There is a whole universe of uses that might technically violate copyright, might technically not fit into di minimis, first sale or fair use – but these are also uses that no one would ever find out.
I get it. You may feel like you can't tell the difference between the kind of uses that no one would give a shit about; the uses that might attract a bone-chilling lawyer letter; and the uses that might land you in court. I'm sorry, but I can't help you figure that one out. I'm not a lawyer. Even if I was, I'm not your lawyer.
This is one of those areas where I break with my friend, the wonderful John Hodgman. On his indispensable podcast "Judge John Hodgman," he frequently admonishes people who are uncertain if they're overstepping a bound in a commercial establishment to ask an employee for permission. For example: should you fill up a water glass with soda water from a self-serve dispenser?
https://maximumfun.org/podcasts/judge-john-hodgman/
John says you should always ask the cashier. But I've worked jobs like that, and I can tell you that there were plenty of jobs where my boss felt very strongly that taking $0.0000001 worth of water and bubbles without paying for it was theft…and where I thought my boss was a dick for thinking that. If I pretended I didn't see you getting a glass of fizzy water, the worst that would happen is my boss would tell me to keep a closer eye on the customers lest they steal his precious CO2. But if you asked me whether you could fill your glass, and my boss caught me saying yes, I'd be fired.
There's a lot of normal, perfectly fine stuff that technically violates copyright that I can't give you permission to do, because I've signed a contract with my publisher. If you ask me, I'll have to ask my editor, who will say no, even though he thinks it's fine, too. If I push it, he'll have to ask the lawyers, who will almost certainly also say no, even if they think it's fine, because it doesn't make sense to spend hours papering over a legal agreement with someone who wants to sell seven copies of a book at an anarchist book-fair or upload a couple chapters of a book to a school's intranet.
Are there instances in which you might misjudge which category your use falls under and end up in court? I guess so. But if that's your concern, asking my permission does no good, because I'm just gonna tell you no.
Life is hard.
Read books.
Hey look at this (permalink)

- AOC Must Run For President https://www.hamiltonnolan.com/p/aoc-must-run-for-president
-
Role confusion: one more reason we can’t trust LLMs https://designingsecuresoftware.com/writings/role-confusion/
-
Ida Tarbell: The Journalist Who Took Down Rockefeller https://prospect.org/2026/07/31/ida-tarbell-journalist-who-took-down-rockefeller/
-
Medusa Joins the Club https://longforgottenhauntedmansion.blogspot.com/2026/07/medusa-joins-club.html
-
Hot Centrist Summer Was a Bust https://prospect.org/2026/07/31/democrats-donor-base-establishment-progressive-hot-centrist-summer-was-a-bust/

Object permanence (permalink)
#25yrsago RIP, Poul Anderson https://www.locusmag.com/1997/Issues/04/Anderson.html
#25yrsago Talking P2P at PC Forum https://web.archive.org/web/20010820163912/https://www.edventure.com/pcforum/transcript.cfm?Counter=13
#25yrsago CD DRM cracked in 2 weeks https://web.archive.org/web/20010803144120/http://www.oreillynet.com/cs/weblog/view/wlg/533
#20yrsago Waitress cards drinker, is handed her own stolen ID https://web.archive.org/web/20060901042515/http://www.thedenverchannel.com/news/9606436/detail.html
#20yrsago How POWs in a Nazi camp got a Disney insignia https://web.archive.org/web/20061209200825/https://blog.modernmechanix.com/2006/08/01/wwii-pows-get-a-disney-designed-logo/
#20yrsago Fixies illegal in Portland https://bikeportland.org/2006/07/28/judge-finds-fault-with-fixies-1727
#15yrsago Freedom of Information requests show that UK copyright consultation was a stitch-up; Internet disconnection rules are a foregone conclusion https://torrentfreak.com/digital-economy-act-a-foregone-conclusion-110731/
#15yrsago What Murdoch’s media empire did: the big picture https://web.archive.org/web/20110805111419/http://blogs.alternet.org/speakeasy/2011/07/27/what-rupert-murdoch-means-for-you-personally/
#15yrsago Flowchart shows the complexity of NZ Internet Disconnection copyright law https://web.archive.org/web/20111105044005/https://lawgeeknz.posterous.com/copyright-infringing-file-sharing-amendment-a
#15yrsago Married lesbian couple rescued 40 teenagers from drowning during Utøya shooting https://www.lgbtqnation.com/2011/07/married-lesbian-couple-saves-dozens-during-norway-shooting-rampage/
#15yrsago Stephen Fry debating Ann Widdecombe on the worth of the Catholic Church https://www.youtube.com/watch?v=9fN3zDtfivc
#10yrsago Jacksonville police pension fund blows $1.8M worth of tax-dollars fighting open records requests https://web.archive.org/web/20160804040211/http://jacksonville.com/news/metro/2016-07-30/story/open-government-lawsuits-against-city-pension-fund-cost-taxpayers-more-2
#10yrsago A profile of Moxie Marlinspike: the seagoing anarchist cryptographer who brought private messaging to millions https://www.wired.com/2016/07/meet-moxie-marlinspike-anarchist-bringing-encryption-us/
#10yrsago Burying the past in glass coffins: Victoria & Albert museum bans sketching in temporary exhibitions https://www.theguardian.com/artanddesign/2016/apr/22/va-museum-no-sketching-signs-draconian?CMP=share_btn_tw
#10yrsago Hugo Gernsback’s introduction to the first issue of Amazing Stories, 1926 https://brucesterling.tumblr.com/post/148297242233/a-new-magazine-announced-by-hugo-gernsback
#10yrsago Afterbrexit: Scotland trolls Theresa May by passing laws she has ridiculed https://www.nakedcapitalism.com/2016/08/scotland-disses-theresa-may-by-reviving-anti-inequality-law-she-loathes.html
#5yrsago Managing aggregate demand https://pluralistic.net/2021/08/01/managing-aggregate-demand-part-iv/
#1yrago Mattie Lubchansky's 'Simplicity' https://pluralistic.net/2025/08/01/ecosexuality/#nyc-ast
Upcoming appearances (permalink)

- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/

Recent appearances (permalink)
- Why AI Won't Replace Workers, But Will Crash The Economy (Smart Cookies)
https://www.youtube.com/watch?v=rRRmUuxJolY -
AI and the Enshittification Era (The Weekly Show with Jon Stewart)
https://www.youtube.com/watch?v=-dAIJRjb-Bw -
AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE

Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com

Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027

Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING

This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X

AlphaFold was a machine learning system from Google Deepmind. It did protein folding.
It was usably good at guessing protein structures. It caught public attention by doing really well in the Critical Assessment of Structure Prediction benchmarks.
AlphaFold did some useful work — mostly as an extra to help biologists predict a structure they were working on. A lot of biologists didn’t find it useful, some did. That’s fine.
I’m saying “was” and “did” about AlphaFold because Google killed it. [FT, archive]
The original founders of AlphaFold have mostly been reassigned over the past year. Google moved several of them to work on the Gemini chatbot. About a quarter left Google entirely.
In 2024, AlphaFold creator John Jumper and DeepMind CEO Demis Hassabis shared the Nobel Prize in Chemistry for their work on AlphaFold! Because the 2024 Prize committee gave multiple prizes for AI-related work, whether it made sense or not.
Google moved Jumper to working on … fixing AI computer coding in Gemini. He left Google for Anthropic shortly after. A DeepMind employee told the FT that:
their departures had sparked surprise internally.
I’m shocked the Nobel-winning researcher wanted to do research, not product work.
Google’s real use case for AlphaFold was not the biology. It was to have a handy excuse for the excesses of the AI bubble.
Whenever chatbots are being garbage, some bozo will always say: what about medicine, huh? What about AlphaFold, huh?
Google was careful not to quite claim that AlphaFold would cure cancer. There’s laws about that. But they did talk about AlphaFold and cancer in the same press release blog posts a whole lot.
Even Sam Altman tried it on for OpenAI: [Twitter, archive]
grind for a decade trying to help make superintelligence to cure cancer or whatever
Whenever an AI bozo says AI will cure cancer, they’re saying out loud what Google was trying to imply quietly. But even that hype no longer does enough work for Google to keep funding it.
What now? Google’s Isomorphic Labs is trying to commercialise AlphaFold output. The AlphaFold models and data continue to be developed at OpenFold, which is useful enough it’s attracted a pile of sponsors. [OpenFold]
But to Google, not even a Nobel Prize was worth keeping AlphaFold around. Yeah, we’re gonna put you on the chatbot, mate. That’s fine, right?
It’s pledge week at Pivot to AI! If Pivot brightens your day, please do put $5 into the Patreon. Tell your friends!
Mikkel Rev returns to A Strangely Isolated Place with Evocation, his third full-length album shaped deep within the forests of Norway.

Since Mikkel’s debut, The Art of Levitation first arrived in 2023, Mikkel has been quietly building his own corner of the ASIP catalogue. Last year’s Journey Beyond expanded that vision further, revealing an artist increasingly comfortable balancing the emotional pull of early trance with a more reflective, ambient-leaning approach. While his work elsewhere naturally gravitates towards the dance floor through his own collective, Ute Recordings and other club-focused outlets, his ASIP releases have always evolved differently. Beginning with a larger body of material that’s gradually shaped together, each album seeks to find a narrative without a dancefloor in place; one that moves naturally between momentum and stillness, carrying something of the spirit found in those early-’90s records that drifted effortlessly between peak-time energy and the quiet hours in room two.
Long-form compositions like “Step Inside” and “MRI” favor gradual development over immediate impact, while “Dream Sand” introduces shimmering rhythms that subtly shift the album’s momentum and pace. The piano-led “The Infinite” offers a definitive nod to the enduring emotional pull of classic trance before “Sanitorium” closes the record with one of Mikkel’s most restrained and affecting pieces to date.
Evocation continues Mikkel Rev’s remarkable run on ASIP, extending a catalog where echoes of trance’s formative years find new expression through the communal energy and natural surroundings of the Nordic forest gatherings that have become an integral part of his world.
Ventral Is Golden returns on artwork duties, with Lupo handling the mastering and cut. Released on August 28th as a gatefold double LP on dusty purple smoke and digital.
Buy at Space Cadets (UK/EU orders)
RSVP to Bandcamp listening party


In February, a content creator from New Zealand named Harry Chang posted a YouTube video called “This AI TikTok Shop Video Made Me $67,420 (Here’s How).” In the video, Chang and another YouTuber, Jimmy Farley, describe how Chang created a viral marketing video for a supplement company called Rosabella called the “Nigerian SECRET to CLEAN LIVER!!”
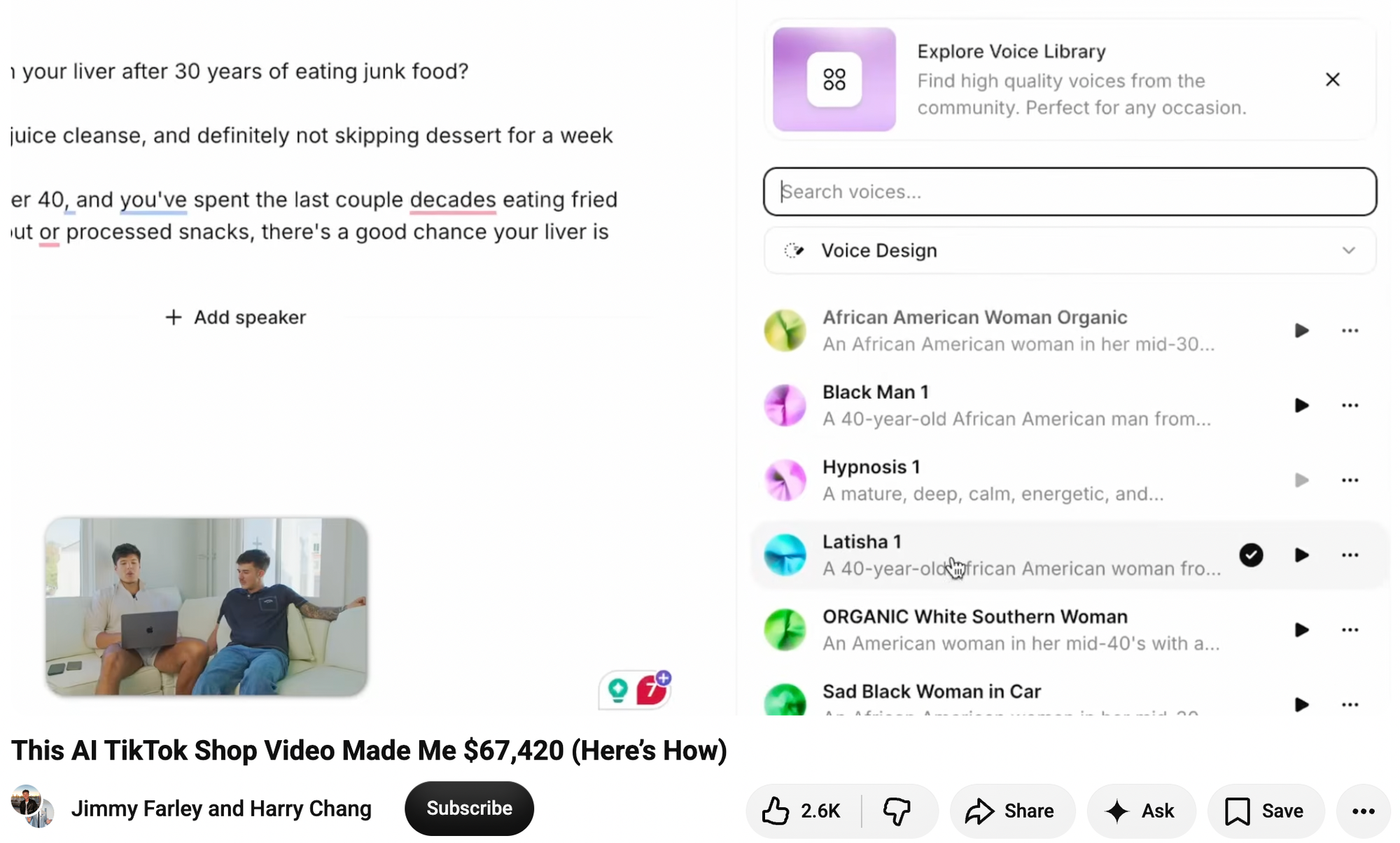
Chang explains that he copy-pasted the script from a video posted by an account called “liverboosthub11” and tweaked it to suggest the supplement he was marketing is “something that’s been used in Asia or Africa for a long time that a lot of people don’t know about in America.”. In Google’s VEO 3, he created an AI-generated Black woman wearing a surgical mask in the foreground of the video, pointing up at another AI-generated Black woman (created in a tool called HeyGen) wearing a pink dress and standing on a stage. He directed the woman in the foreground to have a “strong African American accent,” and to say, “Why is nobody talking about what this hoe said?! If you’ve got issues with that belly, must watch!”
“Builds curiosity, builds intrigue,” Chang says about his creation. “People want to know, ‘damn, what did she say? What did that ho say?’” To make the AI-generated woman on stage read the script he took from liverboosthub11, he pulls up the popular AI voice generator ElevenLabs. He scrolls through a list of voices that he had created, including “African American Woman Organic,” “Black Man 1,” “ORGANIC White Southern Woman,” and “Sad Black Woman in Car.” He settles on a voice called “Latisha 1.” He syncs the voice with the AI-generated videos he created in the video editing software CapCut. This AI video goes on to get 1.3 million views on TikTok and apparently earned him tens of thousands of dollars in affiliate sales.
In another video, Chang explains how he has made tens of thousands of dollars using AI influencers. “I’ve even had my clients buy me Rolexes for selling so much of their products,” he says.
The video’s title is “How I print $51,000/month profit with AI influencers (feels illegal).”
A new lawsuit argues that the strategy is, indeed, illegal. (After 404 Media asked for comment for this story, several of the YouTube videos mentioned in this article were deleted).
In February, a supplement company called Humann sued a competitor called Ambrosia Brands because Ambrosia, through the supplement company called Rosabella, allegedly directed and influenced the creation of hundreds of TikTok Shop videos and ads featuring AI-generated “doctors” that oversold the supposed benefits of Rosabella’s products. Rosabella’s AI marketing practices have previously been written about by 404 Media and The New York Times, but were most thoroughly explored in an excellent episode of the podcast Conspirituality.
The lawsuit reveals new details about how this group of 20-something YouTubers built their army of AI-generated influencers. In practice, Rosabella is more of a social media AI content hustle and AI marketing exercise than a supplement company. What happened in this case is the same type of spam and buy-my-course to get-rich-quick strategy that we have repeatedly written about, only this time the slop is being used to shill supplements largely to the elderly. Rather than payouts coming from the number of views a video gets on social media, the payouts are commissions on products sold. The lawsuit was spotted by the lawyer Rob Freund on X.
“All these guys are ex-dropshipping guys,” Mallory DeMille, who studies the wellness and supplements industry and who reported the episode of Conspirituality, told 404 Media. “They could have chosen anything to sell to make AI content out of, but they chose supplements, and it’s interesting they chose supplements because it’s such an unregulated market where [they] can basically pump out whatever product they wanted to with very little oversight. On the marketing side, it’s also pretty unregulated and there’s a lot of real [human] influencers making unfounded health claims without there being many consequences. In terms of ease of making money — wellness, they chose this industry for a reason. I think it’s pretty seamless, has proven to be seamless and now they’ve sold a fuckton because of how easy it is.”
The lawsuit highlights a series of TikTok videos—like the ones I described above, and most of which are still online—featuring AI-generated doctors, TED Talk-style speakers, and videos that are essentially identical to the ones Chang has repeatedly taught people on YouTube how to make. And hundreds of additional videos promoting Rosabella that are not highlighted in the lawsuit are trivial to find on TikTok. Many of them have hundreds of thousands or millions of views and seem to make wild promises about what Rosabella supplements can do.

In another video, Chang explains why his favorite products to sell fall into the “elderly health” category: “It’s an extremely profitable niche, especially in the U.S., guys.”
“In the U.S., they have very high demand for health products,” he says. “They don’t have any free healthcare, right? People over 35 literally are very concerned about their health […] You have moms who buy 100 supplements and put them all in their cupboard. It is crazy. It’s crazy.”
“When you have such a high, problem-solving niche, it’s very easy to write scripts for, very easy to innovate, and just continuously make money,” he says, adding that he usually generates AI influencers who themselves look old.
“They’re relatable and credible,” he says of three older-looking AI people he shows on screen, one of which is shilling beetroot powder from Rosabella. “Why? Because they are old. People are more willing to listen to old people only because they see them as more wise and intelligent […] and look how credible they look. They’re speaking on stage like TED Talk-type style and they’re more relatable because they’re more similar to the age we want to target. If you’re trying to sell health products to a 50-year-old, well, make your avatar 50 years old.”
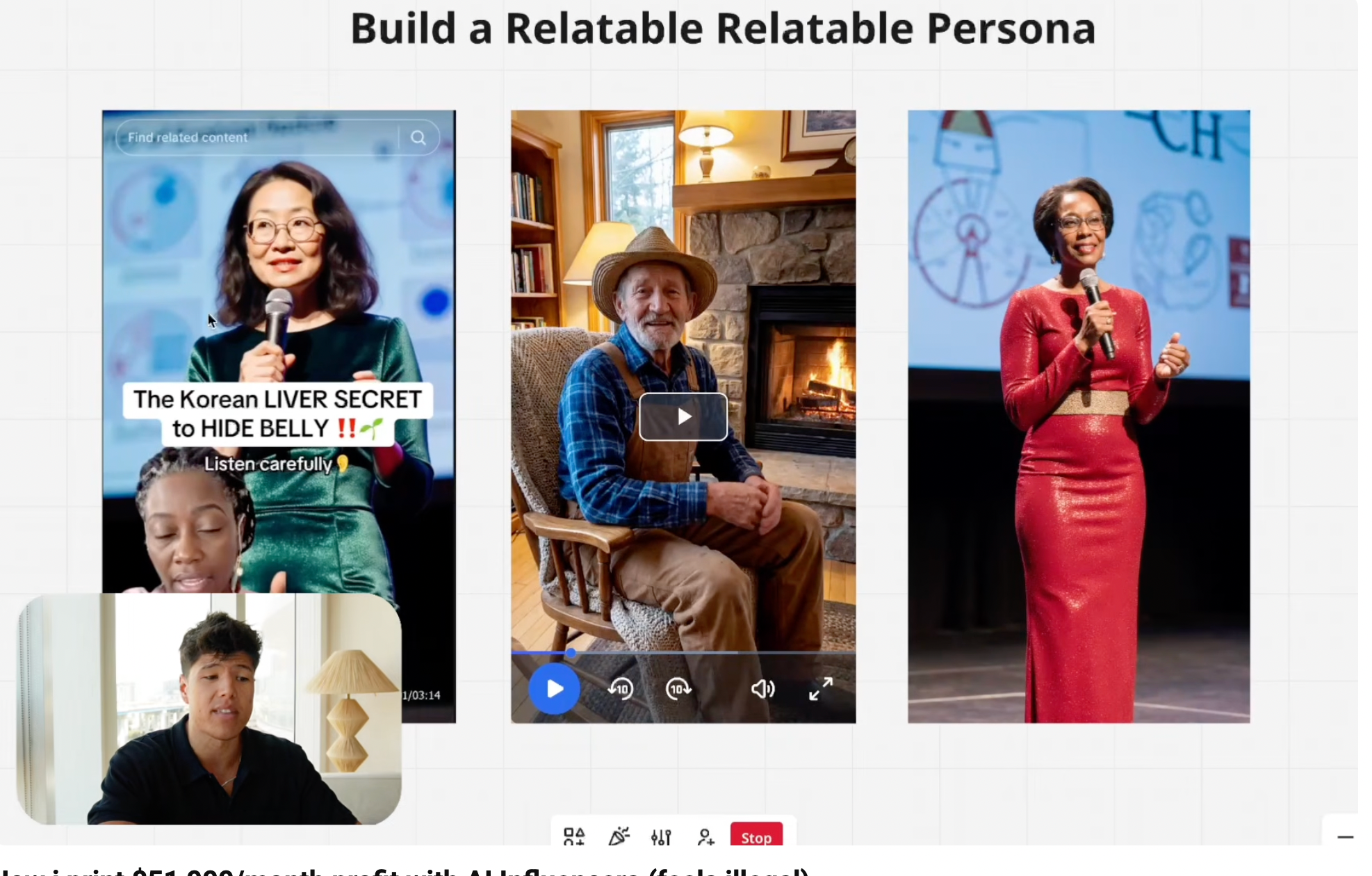
On TikTok, Rosabella used a mix of paid influencers and AI-generated characters to make unfounded medical claims about its products and about beetroot more generally, the lawsuit alleges. “In several TikTok Posts, the post purports to show a doctor, medical professional, or other medical authority espousing the health benefits of Defendant’s products. All or nearly all of the ‘doctors’ featured in the TikTok Posts are AI-generated and fictitious, making the claims in the advertisement false and/or misleading,” the lawsuit notes. “For example, in a June 14, 2025 TikTok post, influencer ‘poormaninla’ purports to depict a doctor in a whitecoat that promotes the alleged health benefits of Defendant’s products. Before the ‘doctor’ begins speaking, a separate speaker is imposed on the screen in a surgeon’s or nurse’s scrubs.”
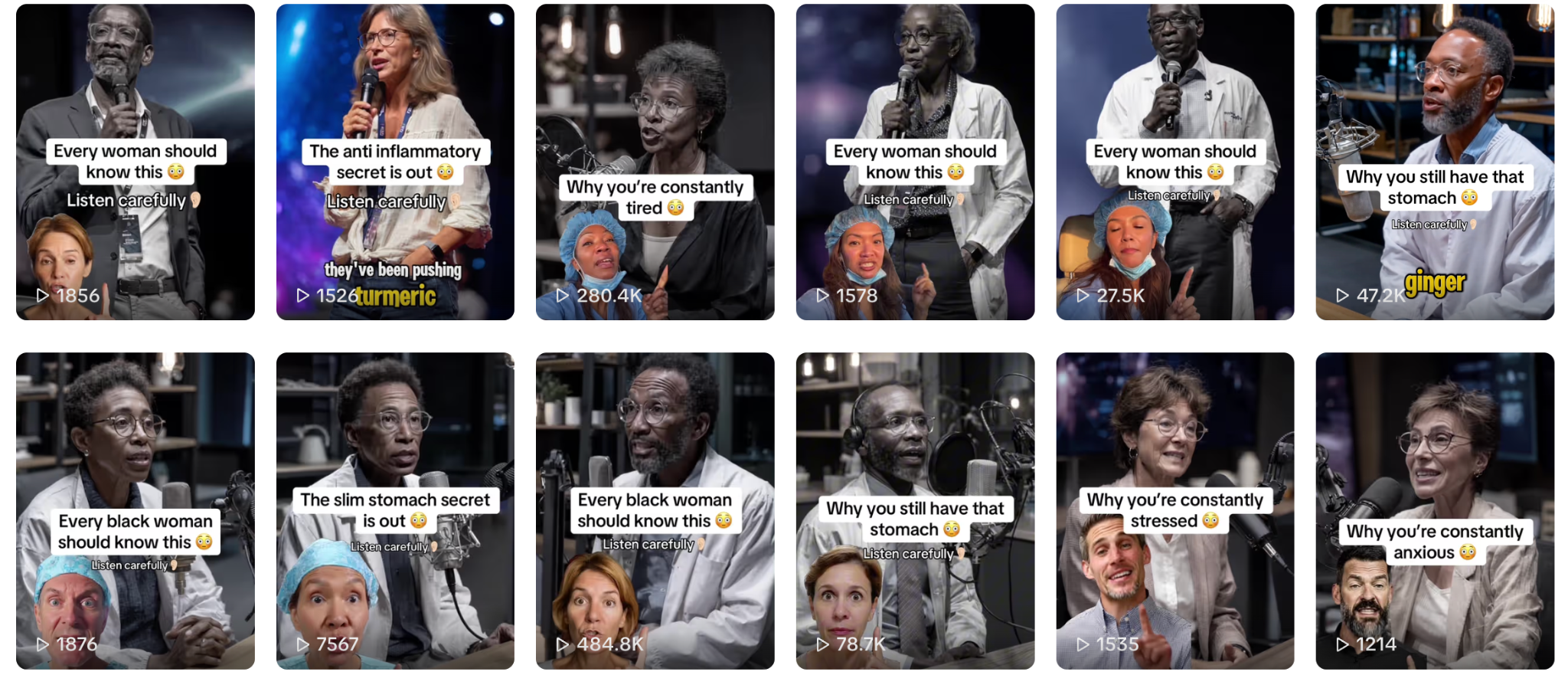
The “poormaninla” account is still up on TikTok and its videos are almost entirely AI-generated. Several of the videos have hundreds of thousands of views. “The best food for Black women to eat if they want a slim stomach is not turmeric, it’s not ginger, and it’s definitely not blueberries. Just one teaspoon of this food reduces gut inflammation,” an AI-generated man in a lab coat says in one.
You can see some of the videos promoting Rosabella here:
The lawsuit argues that Rosabella is “orchestrating a misinformation campaign on TikTok through its network of influencers,” who “make various misrepresentations about the health and wellness benefits of Defendant’s beetroot products, which are entirely unfounded.” The lawsuit alleges that Rosabella, through a private Discord channel, offered extensive coaching to content creators on how to make AI-generated TikTok ads; that many of these ads featured fake doctors and other AI-generated people who were made to look authoritative; that some of these videos were racist; and that when people bought Rosabella products through TikTok Shop links on those videos, the creator of those videos would earn a commission. Humann’s argument is that Rosabella’s “false and misleading representations undermine public confidence in other beet products, like Humann’s SUPERBEETS products.”
Ambrosia says, essentially, there is no evidence it told people what to do in the Discord channel. In court filings, Ambrosia claims that Humann “fails to allege any facts that plausibly show Ambrosia induced or materially contributed to the third-party conduct it complains of.” It remains unclear whether what Rosabella was doing is illegal in the unregulated world of supplements in the U.S., or whether a competitor could win a false advertising lawsuit like this. But there is no doubt about Rosabella’s strategy, what their motivations are, and the incredibly close connection between Rosabella and the network of content creators who made, conservatively, hundreds of AI-generated videos.
The lawsuit highlights how common fully AI-generated marketing has become on platforms like Instagram and TikTok, and nods at, but does not dive into, the complicated web of YouTube hustlebros that have largely given rise to this practice, and the social media platforms that have incentivized and promoted AI-generated spam and fly-by-night supplement companies. Rosabella is a company that has already been subject to an “extensively drug-resistant salmonella” recall by the Food and Drug Administration. But it is maybe better understood not so much as a supplement company but more as a branding exercise and vertical video content hustle by the same types of AI spammers and buy-my-course bros we’ve written about numerous times over the last few years.
In a video about “why you need to be working with Rosabella” qposted by an account called “Luca Washenko” on the online course sales platform Whop, a man brags “we paid out over $400,000 last month to creators.” He says that individual people have made more than $300,000, and shows “proof and dates of our creators getting tons of views consistently. Got 55 million right there […] I am one of the lead coaches in the Rosabella server.”
But Washenko isn’t just a creator helping to advertise Rosabella. He is the company’s founder. A YouTube video repeatedly alludes to this, and mentions how much money he and his army of affiliate creators have made selling Rosabella products on TikTok Shop. Washenko is also listed as the cofounder of Rosabella on several trademark filings I found, and his LinkedIn lists him as the founder of “MNY Ventures,” a company that has the Rosabella logo on LinkedIn. Clicking through “MNY Ventures” goes to a LinkedIn page for “Rosabella,” which has several job listings for AI video editors: “MNY Ventures is home to one of the fastest-growing supplement brands in the world, built on the back of a high-performance, results-obsessed culture. We don't just create ads; we create market-leading campaigns that generate massive revenue,” one of the LinkedIn job listings reads. “Your mission is to lead the production of our high-converting AI videos quickly and at high quality. You will be responsible for consistently creating on-brand and compliant video content based on proven formulas designed to maximize reach, ensuring MNY Ventures maintains its position as the #1 leader in AI video marketing for e-commerce.” The listing adds the person will need to produce “10 high-quality AI videos per day, following our preset scripts and styles.”
In a video called “Inside a TikTok Shop Meetup with Million Dollar Creators,” there is no doubt about Rosabella’s strategy, Washenko’s motivations, or Rosabella’s close relationships with the people spamming AI-generated content shilling its products. Rosabella is just the latest of Washenko’s creations. His previous claim-to-fame was selling caffeine vapes on TikTok.
“There have been creators that are now millionaires from working with Rosabella,” Washenko says in the meetup video. “It’s one thing if you make money, it’s another thing if you can help everybody around you make money. An event like this where you can go face-to-face and shake hands with people and they say, ‘You’ve changed my life.’ And I’m like ‘You’ve changed mine.’ Those are the moments that are so special, especially when everything is remote. It’s online. It’s Discord, that’s one thing. You look them in the eye and they say, ‘I was able to pay my mortgage when I lost my job because I was making videos for you.’ That’s a different feeling.”
Washenko explains there are two reasons why people should make content promoting Rosabella: “If you want to be the Tiger Woods of creator, if you want to be the Caitlin Clark, you want to be the Michael Phelps, you want the golden rings you want to be the greatest, to be the number one, that’s what we’re all about. That’s the Rosabella family,” he says. “Along the way, you’ll make a ton of money.”
Later in the video, Washenko stands on stage addressing a crowd, shouting out “all the people I’ve been talking to on Discord from day one, from 18 months, I started Rosabella in my mom’s basement.” He shouts out all the creators who he’s helped make rich and who helped make him rich. He then says there’s one other “person I want to shout out today.” He calls up Harry Chang, the YouTuber who made the video “How I print $51,000/month profit with AI influencers (feels illegal).” Washenko presents him with a Rolex. “I cannot be any more proud to be working on a brand with you,” and for that, I want to give you this watch today. It’s a Rolex, by the way.”
After 404 Media asked for comment on the video, it was deleted from YouTube.
DeMille, who reported the episode of Conspirituality diving into Rosabella, Washenko, and Chang, told me the men are “just actively bragging about it online. I can’t believe they’re openly talking about it like this.”
“A lot of the videos of these AI slopfluencers, they’re using narratives that real-life wellness influencers have seen success using, but they’re taking these narratives and inputting them into whatever AI systems they’re using and making people look whatever age they want,” DeMille said. “There’s no thought behind it. There’s no anything behind the content that they’re turning out. These videos they’re replicating in their AI machines are also being used to sell something, but it’s being generated into something else to sell something else. It’s this inception of bad information by people who don’t actually care.”
“These guys behind these AI slopfluencers have proven that they don’t care, and they obviously care more about money and wealth than they do about health,” she added.
Washenko did not respond to a request for comment. Ambrosia Brands did not respond to a request for comment.
A request sent to Rosabella was returned by someone named Emmanuel Obonga. The response said, “We don’t currently have an active affiliate program. However, we’d be glad to keep your information on file and reach out if we revisit or launch one in the future.” In the course of reporting an earlier story about the AI influencer company Doublespeed, Rosabella previously told 404 Media that it “does not use Doublespeed or any AI-generated accounts to promote our products on TikTok or any other platform. We are committed to authentic engagement and building genuine connections with our community. Regarding the claim about being viral on TikTok, this is based on organic content created by real customers and creators who love our product. We’ve seen a lot of positive buzz and user-generated videos that have helped spread the word naturally.”
Daniel Martens, a lawyer representing Humann, told 404 Media Rosabella’s strategy “makes [the] whole supplement industry look bad. If you’re masquerading as a doctor telling consumers how promising all these benefits that don’t exist [are], that’s harmful.


LinkedIn, a social network awash with long AI-generated posts from executives and other corporate workers, has introduced a new button that users can click to flag if a post “seems like AI slop,” according to 404 Media’s own tests.
If you have been anywhere near LinkedIn in the past couple of years, you have undoubtedly seen users posting blatantly AI-generated missives. Often these posts take some sort of news event, and opine on how this relates to thought leadership, or some other LinkedIn brainrot term. It’s also pretty wild the button specifically uses the term “AI slop” and not, say, “It seems this was generated with AI.”